Извлечь выделенный текст
Перетащите файлы DOCX или PDF сюда или нажмите, чтобы выбрать файлы
Извлечение текста, пожалуйста, подождите...
Извлечённый текст:
Ключевые особенности
- Наш инструмент автоматически сканирует PDF и Word-файлы на наличие выделенного текста, быстро собирая важные фрагменты и аннотации. Этот автоматизированный процесс экономит время и снижает риск ошибок, гарантируя, что ни одна важная деталь не будет упущена.
- Инструмент извлекает только выделенный текст — без лишнего содержимого.
- Допускаются только обычные PDF-файлы с выделениями, сканированные PDF (с изображениями внутри) не поддерживаются.
- Этот инструмент для извлечения выделенного текста полностью бесплатен — и останется бесплатным навсегда, мы зарабатываем на рекламе.
- Файлы обрабатываются полностью в оперативной памяти и не сохраняются. Они автоматически удаляются после извлечения текста.
- Этот инструмент использует PyMuPDF и продвинутую обработку DOCX для точного определения и извлечения текста из выделений в PDF.
Как работает извлечение выделенного текста
Принцип работы простой.
- Поддерживается до 5 файлов одновременно, каждый размером не более 15 МБ.
- Нажмите "Извлечь выделенный текст". Появится индикатор загрузки, означающий начало процесса.
- Инструмент покажет извлечённый текст, который можно скопировать или скачать в формате .txt.
Как происходит извлечение текста?
После загрузки инструмент определяет тип файла (PDF или DOCX) и обрабатывает его соответственно. Для PDF используется PyMuPDF для обнаружения выделений и извлечения текста внутри них. Для DOCX инструмент считывает документ и извлекает весь выделенный текст, будь то абзацы или фрагменты. Обработка выполняется в памяти, файлы не сохраняются. Извлечённый текст отображается на экране.
Схема работы извлечения выделенного текста
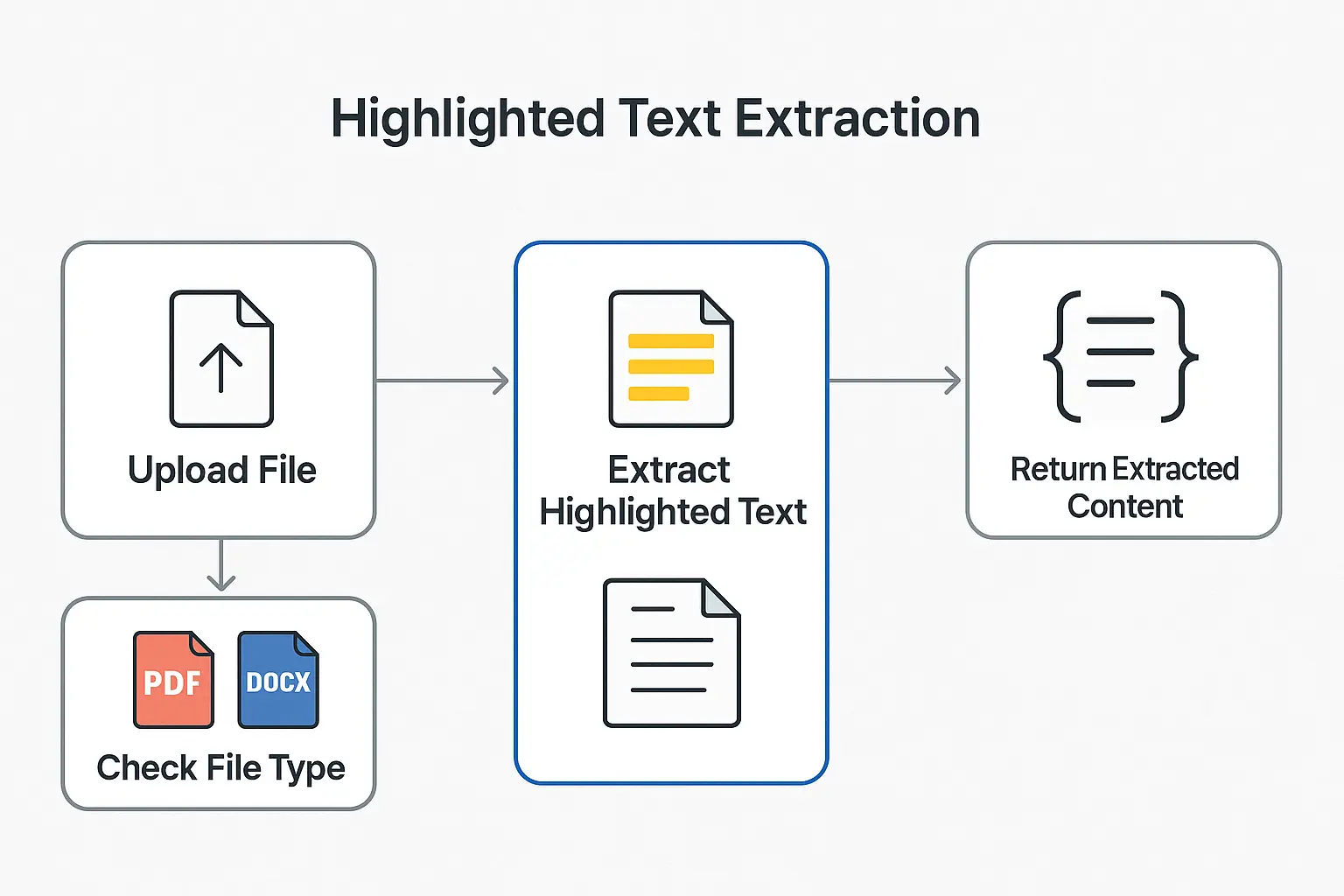
Примеры использования
Ниже приведены лучшие сценарии использования инструмента:
- Извлечение юридических моментов из дел для быстрого анализа.
- Краткое резюмирование ключевых заметок из научных PDF-документов через выделения.
- Извлечение отзывов клиентов из выделенных фрагментов Word-документов.
Почему наш инструмент лучше ручного метода?
- Ручное копирование может занять минуты (или даже часы для больших файлов). Наш инструмент делает это за считанные секунды.
- Ошибки при ручном извлечении могут привести к неточным заметкам. Наш инструмент систематически сканирует и извлекает каждый выделенный фрагмент.
- Быстрое и точное извлечение улучшает организацию заметок и экономит время.
Как мы защищаем ваши данные?
- Используется SSL-шифрование при загрузке и обработке файлов.
- Файлы обрабатываются во временной и защищённой среде.
- После извлечения все данные удаляются с наших серверов.
- Мы соблюдаем ключевые законы о защите данных, такие как GDPR и CCPA. Подробнее в нашей политике конфиденциальности.
Какие форматы файлов поддерживаются?
Инструмент поддерживает форматы .pdf и .docx.
Насколько точно извлекается выделенный текст?
Используются продвинутые алгоритмы, позволяющие извлекать даже едва заметные выделения с высокой точностью. Мы регулярно обновляем их.
Как защищаются мои данные во время извлечения?
Мы используем SSL-шифрование. Все данные хранятся временно и удаляются после завершения процесса.
Что делать, если файл не загружается?
Проверьте формат файла и наличие выделенного текста. Убедитесь, что файл не повреждён.
Как конвертировать или отредактировать извлечённый текст?
Извлечённый текст можно скопировать или скачать в формате .txt, где его можно отредактировать.
Внимание: Сканированные PDF-файлы не поддерживаются. Этот инструмент работает только с цифровыми PDF. Он проверяет наличие выделений. Не используйте зашифрованные или защищённые паролем документы. Мы продолжаем улучшать инструмент.